01 -- ABSTRACT
BUILDING NEXT-GEN AI HARDWARE
At SEMRON, we are transforming AI with breakthrough hardware. Our advanced CapRAM™ technology delivers unmatched compute-in-memory power, significantly boosting performance for AI-driven devices. With our 3D CapRAM™ architecture, we’re pioneering a future where AI can run directly on smartphones, wearables, and headsets without relying on the cloud. We focus on creating hardware that pushes the boundaries of what’s possible, enabling faster, more efficient AI at the edge.
0.2-1 T OPS/mW*
Highest energy efficiency in the world
*full utilization, multi-bit precision (@INT8)
500 M PARAMS/mm²
Highest parameter density in the world
*
*
*
*
02 -- MOTIVATION
AI CHIP COSTS SQUEEZE MOBILE MARGINS
As AI demands grow, chip technologies face rising costs and efficiency challenges. Server-class chips are expensive and power-hungry, while mobile chips lag in performance. Emerging technologies such as RRAM- or SRAM-based IMC approaches promise a slight energy efficiency advantage but fail to match other edge AI constraints: cost and performance density.
5x
COST OF CONSUMER CHIPS
Server-class AI chips can run GenAI models but are typically 5 times more expensive than consumer chips, costing thousands of dollars each and consuming hundreds of watts of power.
70%
LOWER POWER EFFICIENCY
Mobile AI chips can't run GenAI models continuously due to high power consumption, often 70% less efficient than server-class chips.
3x
DEMAND FOR
MULTI-MODEL PROCESSING
AI chips struggle to handle large models and run several at once. The need for triple the performance is critical.
2x
PARAMETER DENSITY GAP
Emerging CRM technologies face challenges with low parameter density, leading to inefficiencies that must be addressed.
NPU IN MARKETS: LIMITED TO MOBILE AI
There is currently no solution for running GenAI models directly on devices like smartphones, smartwatches, smart glasses, or other wearables. In the era of GenAI, offloading workloads to the cloud simply means renting computing power elsewhere, which reduces margins for edge devices.
AI MODEL DATA TRANSFER BETWEEN MEMORY AND PROCESSOR KILLS POWER BUDGET
This challenge led to the development of a new computer architecture: Compute-in-Memory (CIM), also known as In-Memory Computing. Unlike GPUs, where memory and processing units are separate, CIM integrates both functions within the same devices or circuits, allowing them to store and process information simultaneously.

LOWER LATENCY
CIM processes data directly in memory, reducing delays caused by data transfers between memory and processors.
ENERGY EFFICIENCY
By eliminating frequent data movement, CIM significantly reduces power consumption, making it ideal for energy-sensitive tasks
WHILE CONVENTIONAL CIM IS POWER EFFICIENT, IT IS LARGE AND EXPENSIVE
Unlike GPUs with high-density memory, CIM architectures must fit AI models directly into their MAC units. As a result, the size of the AI model directly impacts the required chip area, driving up costs. For instance, the wafer area needed to run a single GenAI model can cost as much as $5,000.

Advancements in memory technology provide the idea for SEMRON's innovative approach to computing operations.

CapRAM™ transforms computing by applying the principles proven in memory technology to operational processing.
03 -- SOLUTION
*
*
CapRAM™: SEMRON's 3D-SCALABLE, ENERGY-EFFICIENT CIM TECHNOLOGY
CapRAM™ breaks away from conventional CiM solutions by using a memcapacitive approach, delivering up to 50x greater energy efficiency than the best memristive technologies. Instead of relying on variable resistors, it uses variable capacitance to store model weights. Current AI chips capable of running GenAI models are prohibitively expensive for mobile devices, often costing thousands of dollars. Since chip costs are driven by wafer area rather than the number of semiconductor layers, the only way to substantially reduce costs is through 3D integration—a challenge we’ve solved with our 3D CapRAM™ technology.

UP TO 50x ENERGY EFFICIENCY
Compared to top-tier memristive solutions, CapRAM™ sets a new standard in energy-efficient computation.
100x LOWER COST PER COMPUTE
3D CapRAM™ reduces AI chip costs through multi-layer semiconductor integration, making high-performance AI accessible for all devices.
200 G OPS/mW EFFICIENCY
Industry-leading energy efficiency for common deep learning models, supporting multi-bit precision.
500 M PARAMS/mm²
Unmatched parameter density, allowing AI models to scale without compromising space or power.
EFFORTLESS AI MODEL DEPLOYMENT ON SEMRON HARDWARE
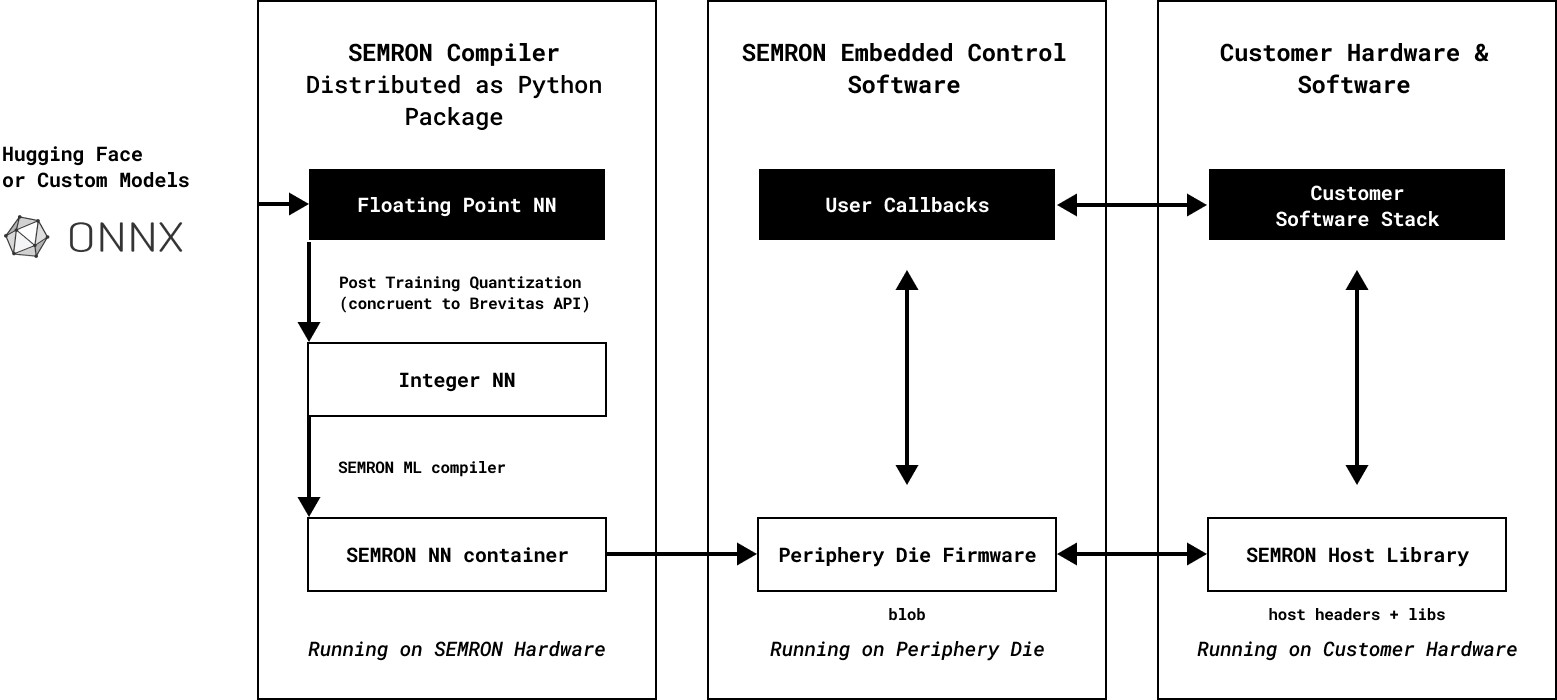
SEMRON provides an easy-to-use workflow for deploying AI models on its hardware. Starting with Hugging Face or custom ONNX models, the SEMRON Compiler converts floating-point models into efficient integer versions using a Brevitas-inspired API. These models are then compiled and packaged into a container to run directly on SEMRON hardware. The embedded control software manages execution, while the SEMRON Host Library ensures seamless integration with the customer’s hardware and software.
CapRAM™
SEMRON's 3D-scalable memcapacitive

0.2-1 TOPS/mW*
Highest energy efficiency in the world
*full utilization, multi-bit precision (8bit INT)

500 M PARAMS/mm²
Highest parameter density in the world
WHILE THE REST OF THE WORLD TALKED ABOUT THE NEXT AI INNOVATIONS, WE FOCUSED ON PERFECTING THE HARDWARE BEHIND THEM.
"While the world marveled at ChatGPT, we were already building the next generation of AI hardware."
SEMRON was founded in 2020 by Aron Kirschen and Kai-Uwe Demasius in Dresden, Germany – Europe's Center of Microelectronics.
With their new technology – to date the most energy efficient semiconductor hardware for AI inference published in Nature Electronics – they quickly gathered the interest of hardware investors and international accelerators, such as Berkeley SkyDeck and Intel Ignite.

BUILDING NEXT-GEN AI HARDWARE
At SEMRON, we are transforming AI with breakthrough hardware. Our advanced CapRAM™ technology delivers unmatched compute-in-memory power, significantly boosting performance for AI-driven devices. With our 3D CapRAM™ architecture, we’re pioneering a future where AI can run directly on smartphones, wearables, and headsets without relying on the cloud. We focus on creating hardware that pushes the boundaries of what’s possible, enabling faster, more efficient AI at the edge.
01 -- ABSTRACT
0.2-1T
OPS/mW*
0.2 - 1.0T OPS/mW*
Highest energy efficiency in the world
*full utilization, multi-bit precision (@INT8)
500M PARAMS/mm²
Highest parameter density in the world
AI CHIP COSTS SQUEEZE MOBILE MARGINS
As AI demands grow, chip technologies face rising costs and efficiency challenges. Server-class chips are expensive and power-hungry, while mobile chips lag in performance. Emerging technologies add to these issues with inefficiencies in parameter density.
5x
COST OF CONSUMER CHIPS
Server-class AI chips can run GenAI models but are typically 5 times more expensive than consumer chips, costing thousands of dollars each and consuming hundreds of watts of power.
70%
LOWER POWER EFFICIENCY
Mobile AI chips can't run GenAI models continuously due to high power consumption, often 70% less efficient than server-class chips.
3x
DEMAND FOR
MULTI-MODEL PROCESSING
AI chips struggle to handle large models and run several at once. The need for triple the performance is critical.
2x
PARAMETER DENSITY GAP
Emerging CRM technologies face challenges with low parameter density, leading to inefficiencies that must be addressed.
NPU IN MARKETS: LIMITED TO MOBILE AI
There is currently no solution for running GenAI models directly on devices like smartphones, smartwatches, smart glasses, or other wearables. In the era of GenAI, offloading workloads to the cloud simply means renting computing power elsewhere, which reduces margins for edge devices.
AI MODEL DATA TRANSFER BETWEEN MEMORY AND PROCESSOR KILLS POWER BUDGET
This challenge led to the development of a new computer architecture: Compute-in-Memory (CIM), also known as In-Memory Computing. Unlike GPUs, where memory and processing units are separate, CIM integrates both functions within the same devices or circuits, allowing them to store and process information simultaneously.
LOWER LATENCY
CIM processes data directly in memory, reducing delays caused by data transfers between memory and processors.
ENERGY EFFICIENCY
By eliminating frequent data movement, CIM significantly reduces power consumption, making it ideal for energy-sensitive tasks
WHY CONVENTIONAL CIM IS NOT SUFFICIENT
There is currently no solution for running GenAI models directly on devices like smartphones, smartwatches, smart glasses, or other wearables. In the era of GenAI, offloading workloads to the cloud simply means renting computing power elsewhere, which reduces margins for edge devices.
WHILE CONVENTIONAL CIM IS POWER EFFICIENT, IT IS LARGE AND EXPENSIVE
Unlike GPUs with high-density memory, CIM architectures must fit AI models directly into their MAC units. As a result, the size of the AI model directly impacts the required chip area, driving up costs. For instance, the wafer area needed to run a single GenAI model can cost as much as $5,000.
Advancements in memory technology provide the idea for SEMRON's innovative approach to computing operations.
CapRAM™ transforms computing by applying the principles proven in memory technology to operational processing.
03 -- SOLUTION
*
*
CapRAM™: SEMRON's 3D-SCALABLE, ENERGY-EFFICIENT CIM TECHNOLOGY
CapRAM™ breaks away from conventional CiM solutions by using a memcapacitive approach, delivering up to 50x greater energy efficiency than the best memristive technologies. Instead of relying on variable resistors, it uses variable capacitance to store model weights. Current AI chips capable of running GenAI models are prohibitively expensive for mobile devices, often costing thousands of dollars. Since chip costs are driven by wafer area rather than the number of semiconductor layers, the only way to substantially reduce costs is through 3D integration—a challenge we’ve solved with our 3D CapRAM™ technology.
UP TO 50x ENERGY EFFICIENCY
Compared to top-tier memristive solutions, CapRAM™ sets a new standard in energy-efficient computation.
100x LOWER COST PER COMPUTE
3D CapRAM™ reduces AI chip costs through multi-layer semiconductor integration, making high-performance AI accessible for all devices.
200 G OPS/mW EFFICIENCY
Industry-leading energy efficiency for common deep learning models, supporting multi-bit precision.
500 M PARAMS/mm²
Unmatched parameter density, allowing AI models to scale without compromising space or power.
EFFORTLESS AI MODEL DEPLOYMENT ON SEMRON HARDWARE
SEMRON provides an easy-to-use workflow for deploying AI models on its hardware. Starting with Hugging Face or custom ONNX models, the SEMRON Compiler converts floating-point models into efficient integer versions using a Brevitas-inspired API. These models are then compiled and packaged into a container to run directly on SEMRON hardware. The embedded control software manages execution, while the SEMRON Host Library ensures seamless integration with the customer’s hardware and software.
CapRAM™
SEMRON's 3D-scalable memcapacitive
0.2-1 TOPS/mW*
Highest energy efficiency in the world
*full utilization, multi-bit precision (8bit INT)
500 M PARAMS/mm²
Highest parameter density in the world
WHILE EVERYONE TALKED ABOUT AI MODELS, WE FOCUSED ON PERFECTING THE HARDWARE BEHIND THEM.
WHILE THE REST OF THE WORLD TALKED ABOUT THE NEXT AI INNOVATIONS, WE FOCUSED ON PERFECTING THE HARDWARE BEHIND THEM.
WHILE THE REST OF THE WORLD TALKED ABOUT THE NEXT AI INNOVATIONS, WE FOCUSED ON PERFECTING THE HARDWARE BEHIND THEM.
"While the world marveled at ChatGPT, we were already building the next generation of AI hardware."
SEMRON was founded in 2020 by Aron Kirschen and Kai-Uwe Demiasus in Dresden, Germany – Europe's Center of Microelectronics.
With their new technology – to date the most enegery efficeint semiconductor hardware for AI inferencepublished in Nature Electronics – they quickly gathered the interest of hardware investors and international accelerators, such as Berkeley SkyDeck and Intel Ignite.
SEMRON was founded in 2020 by Aron Kirschen and Kai-Uwe Demasius in Dresden, Germany – Europe's Center of Microelectronics.
With their new technology – to date the most enegery efficeint semiconductor hardware for AI inferencepublished in Nature Electronics – they quickly gathered the interest of hardware investors and international accelerators, such as Berkeley SkyDeck and Intel Ignite.
SEMRON was founded in 2020 by Aron Kirschen and Kai-Uwe Demasius in Dresden, Germany – Europe's Center of Microelectronics.
With their new technology – to date the most enegery efficeint semiconductor hardware for AI inferencepublished in Nature Electronics – they quickly gathered the interest of hardware investors and international accelerators, such as Berkeley SkyDeck and Intel Ignite.